
This is OLTP and OLAP and how they connect to SAP.
Both OLTP and OLAP describe how a database is used.
You’ll learn:
- What OLTP is
- What OLAP is
- The difference between them
- Lots more
Let’s get started!
Understand OLAP vs. OLTP and SAP
First, let’s define these terms:
- OLAP
- OLTP
- SAP
OLTP stands for Online Transaction Processing, and OLAP stands for Online Analytical Processing.
As their names suggest, the difference is how you USE them.
OLTP and OLAP are two different types of databases and two different ways of processing data.
Because the data is used differently, it’s structured differently in the database.
OLTP is designed to handle operational requests in a database. These are basically applications used in standard business operations, like production and sales, generating revenues, general administration, and maintenance.
For instance, maintaining sales orders or onboarding a new employee.
OLAP is designed to handle analytical queries in a database. These are the types of requests the database gets from business intelligence and data mining applications.
For example, a business intelligence application provides information about sales orders, such as the net value for a specified timeframe. Or calculating the average salary of new hires over the last five years.
Now that the basics of OLTP and OLAP are covered, SAP is missing:
SAP stands for Systems, Applications, and Products in Data Processing. It’s a HUGE European company that makes business software to manage the various business processes for a company. More on SAP below.
So that was the introduction. Let’s get to the good stuff:
To understand the differences between OLTP and OLAP and how they work in SAP, you need to understand these terms:
- DB (Database)
- DBMS (Database Management System)
- RDBMS (Relational Database Management System)
- DW (Data Warehouse)
- OLTP (Online Transaction Processing)
- OLAP (Online Analytical Processing)
What Is a Database?
A database, also known as a database system, is a collection of structured data and the software used to access that data (the DBMS, or database management system).
Usually the data is stored electronically (there was a time for punch cards).
A database system serves users and applications:
- Save high volumes of data in a way that is
- Efficient
- Consistent
- Permanent
- Provide data subsets in
- Different presentation forms
- Needs-based presentation forms
A database system consists of two parts:
- The actual database in a narrow sense
- A database management system (DBMS).
The actual database is just data stored in a database system, which is managed by the database management system.
Although the entire database system is sometimes just called a database.
Here’s an example of a zoo:
You want to save all the info about the zoo:
- Animal names
- Zoo areas
- Zookeeper wages
#table
This is the actual database data.
A DBMS is needed to store and retrieve the data:
What Is a Database Management System?
DBMS (Database Management System) is the administration software for a database system that manages the database that holds the data.
Whenever someone wants to add information to the database or get information from it, they submit a request to the DBMS.
The DBMS:
- Takes the request
- Translates the request
- Executes the request, retrieving or modifying data as needed
The data base management system organizes the structured storage of the data and controls access to the database.
To manage and request data, a database system provides a database language, called SQL (Structured Query Language).
To make a DBMS request, you have to use for the request the language used by the DBMS.
Here are 10 examples of database management systems:
- SAP Sybase ASE
- SAP HANA
- Microsoft SQL Server
- Microsoft Access
- Oracle RDBMS
- IBM DB2
- PostgreSQL
- MySQL
- MongoDB
- Amazon RDS
Let’s revisit our zoo example with the above three steps in mind:
You have an application to manage zoo animals, and you add a new animal:
- The application takes the data you provide and sends it to the application server.
- The application server converts the request into the DBMS language to save the data in the database before sending it to the DBMS.
- Finally, the database management system puts the animal data into the database.
What Is a Relational Database Management System?
An RDBMS (Relational Database Management System) is a DBMS that stores data in a relational structure. This means the data is grouped in logical units in tables, and those units link to each other via keys.
The tables are related to each other through keys—what the keys are and how they work is explained in the next zoo example below.
DBMSs are made to retrieve and store data with the presence of redundant data.
RDBMSs are designed to retrieve and store data on a data basis without redundant data.
Let’s say you want to save the zoo animals based on their zoo area:
In a flat non-relational DB, all the animals and their zoo areas would be saved together in one table:
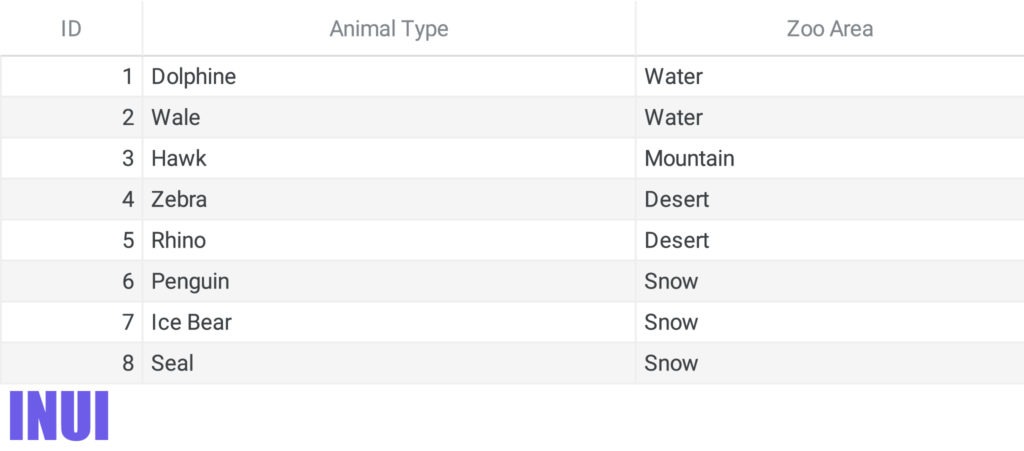
In a relational database, the animals and the zoo areas would be stored in separate tables.
Each entry in the animals table is linked to an entry in the zoo areas table.
The keys are associated with each animal entry in the zoo areas table.
The process of structuring data that belongs together logically into separate tables is called normalization.
Here’s the animals table with zoo area IDs to the zoo areas table:
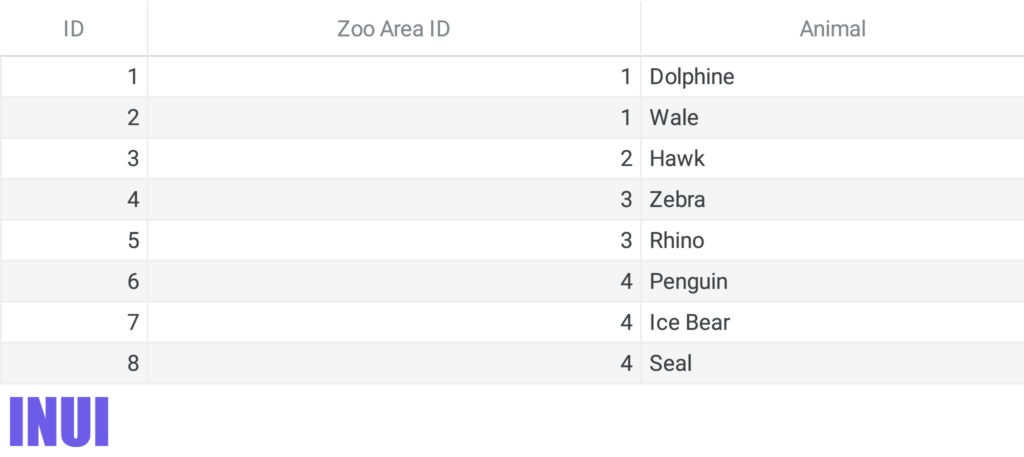
And here’s the zoo areas table:
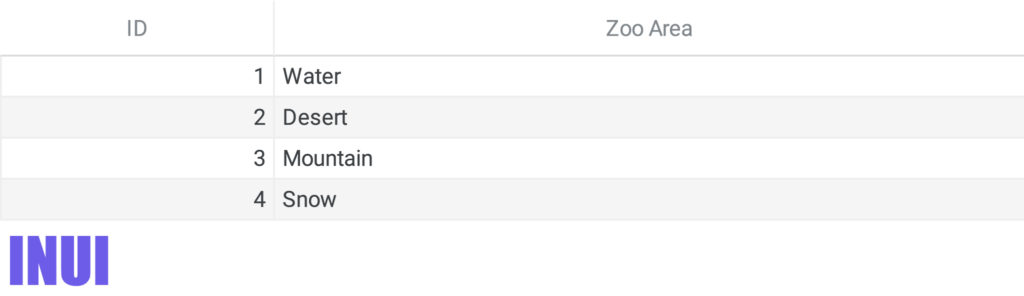
There are two main advantages to relational databases over flat databases.
- Reduced data redundancy
- Improved data integrity
Let’s say you want to add zookeepers to the database, along with the animals and zoo areas.
You want to add who is responsible for which animal and therefore works in which zoo.
In a flat (non-relational) database, you would need to expand your one table.
The table already has data on your animals and zoo areas. The table becomes increasingly crowded, complicated, and redundant:
#flat table
In a relational database, you would just add a table for the zookeepers and use a key to link the entries from the zoo area tables to the zookeeper table.
The key relates each entry in the zookeeper table to an entry in the zoo area table:
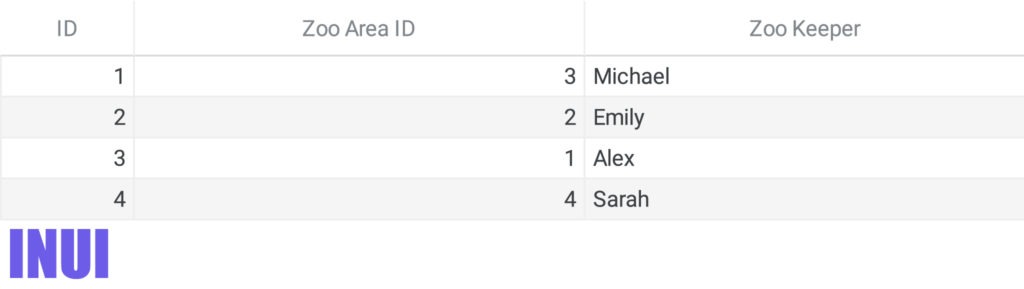
Now you know who is responsible for which zoo area by looking at the relation of the zookeeper table to the zoo area table.
Also, you know which zookeeper is responsible for which animal because of the relationship between the zookeeper table and the zoo area table.
Compared to a DBMS and one table, an RDBMS and its multiple related tables are less compact, less complex, and don’t have any redundant data.
An RDBMS is well structured so it makes sense to a human through its logical groupings, like animals, zoo areas, and zookeepers.
Relational database systems are the most common.
What Is a Data Warehouse?
A DW (Data Warehouse) is basically a relational database. It is a relational database designed to meet the needs of analytical requests.
A data warehouse extracts, transforms, structures, and then stores data from operational databases and external sources.
A data warehouse is for analytical applications.
A data warehouse supports analytical applications in:
- Data consolidation
- Analysis
- Reporting, including the aggregation of data
In turn, these analytical applications help make decisions.
Let’s go back to the zoo example:
You want to go on vacation to Hawaii and you think about closing your zoo for a month.
However, you don’t know which month will be the best to close your zoo in terms of revenue.
You use an analytical application to get the net value of zoo tickets sold for each month over the past two years.
Then you can choose the month with the least net value of tickets sold for your Hawaii vacation.
DWing at its best.
What Is Online Transaction Processing (OLTP)?
OLTP describes databases optimized for operational requests.
These requests are used by far the most frequently in business operations, such as making and selling products, generating revenues, and doing general administrative and maintenance tasks.
Operational requests are NOT from applications that do analytics, such as decision support.
An OLTP database is not a DW.
An OLTP database is made to:
- Process high volumes of requests
- Respond without delay to requests
- Process requests as fast as possible
- Maintain data integrity despite multiple simultaneous requests
The efficiency of an OLTP database is measured by processed transactions per second. Efficient operation is the most important thing in an OLTP database.
OLTP systems are used to serve data to operational applications by providing fast, consistent processing of requests.
As the name suggests, the requests that go to an OLTP database are:
- Transactions
- Processed online
What about transactions and online processing? Let’s do this:
The “Transaction” in OLTP
A transaction is a request to a database and it’s a logical unit.
This means that after the request is processed successfully, the request leaves the database consistent.
Consistent means that the data is only changed if the database allows it, so data integrity is preserved.
Data integrity in a relational database is maintained if:
- Attributes are within their value ranges
- Primary keys are unique
- Primary keys are not empty
- Foreign keys are either empty or an equivalent primary exists
- Custom integrity rules are met
Basically, either a transaction is successful or it’s rolled back until the database has the same status as it did if the transaction never went through.
Therefore, if a transaction is canceled during processing, then all the database changes made before it was canceled must be undone.
For instance, the zoo has vacations for the animals:
There’s a sign at each zoo area’s entry letting you know what time the zoo area is on vacation.
Each zoo area gets four weeks’ vacation a year during which the area is closed to visitors.
When vacation’s over, the zoo area opens again.
Let’s impose a little artistic freedom and say the animals can decide on their own when they want the zoo to close so they can go on vacation.
The hawk from the mountain zoo area takes two weeks off from January 01, 2021 to January 14, 2021.
The hawk tells Michael, the keeper of the mountain area of the zoo, about its vacation.
Michael then records the vacation in the mountain’s vacation note.
The transaction for this could look like this:
start of the transaction.
read the field remaining vacations for Chad the hawk.
write January 01, 2019 into the field vacation from for Chad the hawk.
write January 14, 2019 into the field vacation to for Chad the hawk.
end of the transaction.This is a valid transaction that leaves the vacation note consistent if it would be a database.
Suppose the above transaction fails before Michael changes the “vacation to” field: the zoo area gets shut down, and Chad the hawk stays in Bermuda forever.
If this note were left in the database and followed, it would cause problems.
The note would be inconsistant if the transaction failed.
The transaction actually would be no transaction, because of its inconsistent effects on the note.
The invalid transaction would be a mere request to the note.
When a transaction fails, all the changes must be rolled back to maintain the database’s consistency.
Let’s look at another scenario: It’s now June, and Chad the hawk spent two weeks on vacation in January and two more in April.
Unless zookeeper Michael read the field “remaining vacation” before making the vacation request, Chad the hawk could take as much vacation as he wants, even though he’s already used up his four weeks.
Again, it wouldn’t be a transaction but a request, since the request is not consistent.
The transaction doesn’t meet the note’s custom integrity rules, which say that a zoo area can only take four weeks of vacation in a year.
Right?
The “Online” in OLTP
The “online” in OLTP means the transactions in an OLTP system are processed in real-time, without any delay.
The data is processed as soon as the request is made and a reply is given as soon as possible.
An ATM (Automatic Teller Machine) is a good example. As soon as you enter your PIN code, the ATM immediately checks if it’s correct, and then allows you to proceed with your transaction.
Batch processing is the opposite of real-time.
Batch processing involves processing the requests in bulk later. That means the answer to the batch processing is provided later as well.
An example of this is a program that optimizes images: during the day, users upload images to a server, and at night when the server’s load is lower, the program optimizes the new images on the server in batches.
The results are then available the next day once the processing is done.
Real-time processing involves constant user interaction: the user interacts with the application, the application sends the request up to the database, the database processes the request, and it sends a response back to the application.
Batch processing requires a user interaction once, or not at all.
The user starts the batch process, and the system runs it until it’s done.
The other option is that the user schedules a batch request, and it gets handled automatically.
Batch processing dates back to the 60s/70s.
In this time, data and programs were stored on punch cards (can you imagine that? — medieval style), and they were read and processed in batches, often at night.
What Is Online Analytical Processing (OLAP)?
OLAP refers to databases that are optimized for analytical requests.
These are requests from applications that provide decision support, like an app to find out the net value of sales per month or the average number of empty seats on flights.
An OLAP database is NOT an operational database but a data warehouse that takes data from operative databases and restructures it.
As the name suggests, the requests to an OLAP system are:
- Analytical
- Processed online
The “Analytical” in OLAP
An OLAP database is for analyzing data and answering questions about it.
For example, you, as the zoo owner, want to know all about your zoo, such as:
- What is the net value of all the tickets sold last year?
- What’s the average amount of food each animal ate last month?
- Who’s the zookeeper with the most overtime?
An OLAP database is a data warehouse.
A data warehouse extracts, transforms, and stores data from operational databases or external sources.
Imagine an additional layer to the operational database: a DW or an OLAP database.
#chart
An advantage of an OLAP database is that it’s separated from the operational databases.
Therefore, it doesn’t use any of the compute power of an operational database to answer requests, so it doesn’t slow down day-to-day applications.
The “Online” in OLAP
The online in OLAP means the same as online in OLTP: the database is accessed in real time, without any delay.
Data is processed as soon as a request is made, and the results are made available as soon as possible.
Differences between OLTP and OLAP

OLTP, OLAP, and SAP—How Does That Makes Sense?
Until recently, in almost all SAP applications, such as SAP’s ERP and CRM, OLTP databases are used. Data from these databases has traditionally been extracted into OLAP databases used in SAP NetWeaver Business Warehouses.
However, SAP released its own database called SAP HANA in 2010. SAP HANA combines the benefits of an OLTP and an OLAP database in one database.
HANA is an in-memory database.
In-memory means that the data is not stored on a hard drive, but loaded into memory when needed for processing or analysis.
Rather, it exists in memory all the time.
Since the data stays in memory and no hard drive access is necessary, a HANA database is SUPER fast.
This makes it possible to process OLTP and OLAP tasks together in one HANA database—how cool is that?
SAP’s newest ERP and CRM applications use HANA, such as:
- SAP S/4HANA (ERP)
- SAP C/4HANA (CRM)
Thanks for the great explanation.
Thank you, Melford. Glad you like it!